This is a chapter I wrote for a book which may or may not see the light of day. It’s not highly polished, but hey, it’s free! I owe a debt of thanks for
Andy Allan,
Tom Carden and
Paul Jarret for looking over it and offering corrections. Any remaining errors are of course theirs alone.
OpenStreetMap – The Best Map
Maps are broken and most people don’t know it. That’s the problem that OpenStreetMap, the free wiki world map, is designed from the ground up to fix. Maps, like so many technical products, resemble the classic analogy of sausages – very tasty but you don’t want to know how they’re made.
So how are traditional maps made and the data they’re built from collected? There are a couple of answers. Local governments and many specialist agencies in the public sector are deeply interested in the layout of their resources, buildings and so on. Enormous efforts are put in by fire departments, police and others to build highly accurate (the data) and beautiful (the cartography) maps. Supported by the tax payer and having very specific requirements these local maps are often of brilliant quality.
Stepping back for a second, what do we mean by quality? Broadly you can measure it in three ways: depth, coverage and timeliness.
Depth here means the scale, or level of detail, of the map. Do you have all the roads but not the footpaths? Or the country outline but not the roads? Each is useful in it’s own right. Depth can mean the scale of the map, or the z axis or height above the area and what you can see from that height are some ways to think about.
Coverage is the other two spatial dimensions. Do you have the whole planet or just a country in the map? A town or just a few streets? This is the x and y in our cartesian volume.
Lastly, time. You have a complete map at some depth and coverage but it’s from 1956. While very useful if you’re a historian, enough has changed over the years that it’s far less useful today. While 1956 is an extreme to make the point, maps from just a year ago can be equally useless if you live on a road built just 6 months ago.
Physicists will recognise this as the three spatial dimensions plus time, which is a perfectly good analogy for comparing maps.
Back to creating those maps. How is it done? Typically a professional, someone who has a degree in a mapping-related subject with a (more importantly) bright fluorescent safety jacket will spend their time in your area measuring things. They’ll have access to a phalanx of technical goodies to help them measure stuff. What stuff? The names of roads, the width of the road, the outline of a building… pretty much anything you can think of within their targeted map depth.
The technology they will use ranges from a simple compass to advanced GPS and laser distance measurement systems. But that doesn’t really matter, all you need to know is that stuff gets measured and in general it’s been getting more and more accurately measured over the past few thousand years.
In a local government context, the pressures of efficiency and market forces aren’t so keenly felt and thus the time and effort that can be put in to mapping is often significant. In many cases, excessive. This leads to some really beautiful maps. Beauty is generally acknowledged to be hard to define, so for some scope let’s think in terms of a very detailed map with a very good mix of the elemental cartographic inputs – colour, typography, layout and so on
Out in industry, which is a foreign country to academia and government, this isn’t the case. Only a certain amount of time and resources are available to produce a map and the question becomes one of resource allocation. The simplest allocation you can do for every day maps is make them where people are – where they use them. Of course, this is in cities where the population density makes mapping those areas far more efficient than out in the country.
The positive side of neglecting low population areas is that there are fewer customers out there to use those maps, and thus pay for them. Therefore there is little justification for expending equal effort on equal areas.
And here we crash headlong in to one of the traditional Mapping Commandments; thou shall map all areas equally. It is at best a faux pas in mapping circles to suggest mapping the countryside should get fewer resources than the city. The classic pillar of universal service for all, regardless of where you live, is in front of you. Be it the postal service, health care or road quality many people (who often, of course, live in the country) feel that the quality of these kinds of services should be the same everywhere.
It’s an expensive prospect to map the vast expanse of low population density areas across even rich continents and so it doesn’t happen as often. The great thing is that with fewer users, and less to map, there are fewer bugs (inaccuracies) in the maps and of course fewer customers to report them. Problem solved.
Traditionally, mapping resources are organised in a fairly top down way. If you want to map a country you buy a number of cars, fill them with computers and measuring equipment and train people to operate them. Then you tell them where to drive and off they go, reporting back with their data and progress.
Look to windward and we see OpenStreetMap (OSM). At its core OSM is simply a platform for anyone to survey anything they like, anywhere. It’s not dissimilar from platforms used by governments, military and companies everywhere to map. The trick is that we get out of the way.
How do we get out of the way? Well, we don’t require you to be an employee for a start. We’re truly open to all and we’re entirely agnostic about what, how and why you map. That’s very important.
Imagine you are a surveyor out on the road working for a traditional mapping company. Your job is intensely monotonous. Driving around all day in unfamiliar areas you are expected to record details of everything around you in a very structured way. A road is type 22 and a car mechanic shop is type 56. The geometry has to be accurate to some tolerance figure of precision. You’re not allowed to map cycle paths because we’re making a road map for a traditional map company.
That’s intensely constraining and drops all notion of interest and creativity in building a map. On top of that, when your executives show videos of you driving around and cooking your own meals by the side of the road to interested audiences, they make fun of you – how could people be so stupid to live in a car and work for us doing this mindless work?
If by some strong force you overcome these barriers then it’s still not particularly likely you care about the road I live on as much as I do. Therefore you’re less likely to capture good data, which leads to bad maps.
And that’s what counts. Volunteers everywhere love their neighbourhood and we do everything we can to get out of the way between the care you have and encoding it in to a map. You might be a keen cyclist interested in bike routes, a hiker looking for trails or simply need a good base map. In any case, you’re welcome to make the map beautiful in the way you see fit.
Independent of what you map is how you map it. Methods abound. Today you can print out a map, draw any changes on top of it, scan and upload that as your source data. You may use a GPS to create a virtual trail of points like Hansel and Gretel’s trail of breadcrumbs. You could be using a camera to capture geo-referenced photographs of storm drains near you. We don’t mind.
And of course, we don’t mind where you are either. Be it India, Canada or the latest earthquake or typhoon zone. Thus we’re a plateau of freedoms because every single constraint you put on a contributor reduces the amount of contribution from them, and therefore the quality of the final map.
This should feel very similar to wikipedia, which was pretty much the simplest platform you could put together to allow people to write text articles, with very little restriction. It exploded to the position it’s in today based upon those freedoms. Counterintuitive to many, but it will be obvious to our grandchildren.
Metadata in OSM is open ended and as simple as you can get. Any point, line or other feature in the map may have a number of tags which consist of key and value pairs. highway=residential; name=A street for example. The actual keys and their commonly used values evolved simply from people using them and community consensus. To dictate them as in a top-down ontology would have been nuts.
Why? Because for a start no individual could design such an ontology that would be all-encompassing, and even if they could start no two-individuals would agree on it. So we just get out of the way.
The tools used to map, the software, is equally agnostic. A simple XML API exists which anyone can write software talk to. All this means is that there is a published and defined way for your software to magically talk to the map and change it. The definition is as simple as possible and leaves the complexity up to the tags mentioned previously.
The first criticism of OSM was the data quality. How would a map of just a few streets be useful to anyone? This is rooted in old ideas about map quality – that a map can only be useful if it is ‘complete’ and ‘accurate’. Terms I hope to prove here are essentially meaningless in the absolute – no map is complete or accurate – and only useful as relative terms.
The key of course is that a map of only a few streets is useful, if they’re the few streets near you, or those for a given task. Likewise, a few streets near you are useful too… and like a jigsaw puzzle the map can be built that way. Or you could think of OSM as the frankenmap. Built with data from one type and source over here and another over there. Roads in London from someone and pizza restaurants in Berlin from someone entirely different and we integrate and smooth this vast puzzle of data over time in to something coherent and beautiful.
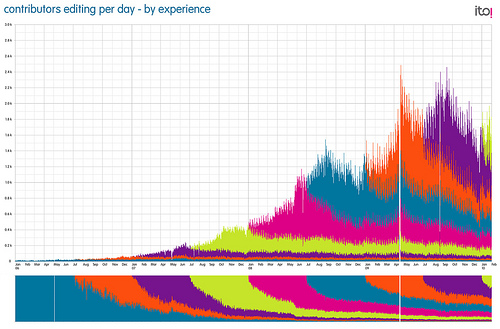
Today the map still isn’t complete and it still attracts this criticism, which displays a stunning lack of perspective. It really matters very little where the map is at any point of time, the point is that unlike almost any other map on or of the planet, it’s continually improving. Exponentially in depth, coverage and timeliness.
A nice retort is that any critique of wiki content is a self-criticism. If you attack an article in wikipedia for missing a fact or having a misspelling then it’s almost certain that fixing it – which you have the freedom to do – is quicker and better than criticising it. Likewise, criticising OSMs completeness is extremely cheap given the freedoms you have to fix it or organise others to fix it.
The second set of critique was that OSMs approach – it’s simplistic tools, lack of complex protocols for communicating map data, undefined ontology and servers which went up and down like yo-yos… …would hobble the project. Let’s take each of those one by one.
Before OSM, tools to build maps were made for professionals. Professionals who spent years learning about maps. Professionals who wore fluorescent jackets. Professionals who have an inherent self-interest in excluding non-professionals. And so the tools were made for them. If you’re going to attract volunteers, you need an entirely different set of tools. You can’t simplify editing tools such that anyone can, off the bat, edit complex freeway intersections successfully, but you can try. And we do.
And of course, the tools are all open and free. If you have a problem with them, you’re free to fix it yourself or encourage/pay someone to do it for you.
Protocols to transmit and mutate map data are generally complex. Overly complex. OSM took the simplest possible approach it could and iterated it, along with much of the project. OSM took an almost naive view of the world in figuring out how to represent it at the beginning – just points and lines between two points. With tags on each, and that was it. Today it’s a little more complicated but not by much. Today we have lines that can go between more than two points!
OSM back then, in 2005 or so, was just as simple in its output. All data, regardless of type was drawn as simple white lines on a murky green background, when it worked. The introduction of colour was a step change in the data that was entered. And thus this is how the project has often overcome its metaphorical bridges. If you provide the output, like rendering motorways differently to roads or providing routing between addresses then people will enter data that is usable. If you expose the tools to visualise the map data (like drawing hotels where they exist) then people will give you the data to make use of them (enter hotels in to the map).
By not constraining contributors with an ontology two things are possible. First, creative and unexpected types of data can be added – and this happens all the time. Second, you expose a playful aspect of the project which is to allow experimentation. The potential downside is people entering bad data on purpose or accidentally, but the upside of the freedoms and the people it attracts more than outweighs this potential problem.
As has been noted many times, the problem of scaling a website to be usable with more users is a good problem to have, compared to the problem of having no users at all. OSM has thankfully had this problem its entire life, and hopefully will always. Hence OSM has often been overloaded. The budget for the entire project over 5 years, excluding conferences and made up entirely of donations, is probably less than a low graduate salary so it’s no wonder. Today, a dedicated team of professional programmers and sysadmins volunteer to maintain OSM and we’re in a much better position.
Let’s talk about efficiency. You can measure mapper efficiency with the amount of stuff they collect (which is presumably accurate) divided by the cost. A traditional mapping company employee may map 1,000 roads a day for a cost, including car and overhead of let’s say $1,000. This gives us an efficiency of $1 per road. OSM of course is an unpaid activity which leads us to divide the number of roads (say 1,000 again) by zero, which is the cost of those roads to collect. Hence OpenStreetMap is infinitely efficient. That’s hard to compete with.
Being serious though, no mapper efficiency comparison is reasonable because of the motivations and data types. OSMers (this is what we call OSM contributors) map many types of data relevant to them at the days and times convenient. The idea of spending 9-5 mapping would instantly turn this in to a job rather than a hobby and thus is very unattractive.
Where does OSM fail? We can draw a further analogy to wikipedia and the over-hyped notion that anyone can break wikipedia by typing nonsense in to any article they please. Wikipedia evolved an idea of the neutral point of view (NPoV) to combat this. Articles should be written as if described by a neutral outsider. Then, many tools on top are used to track maliciously entered data.
This last point is crucial. Many have the notion that finding malicious edits in wikipedia is akin to a needle in a haystack – painful and hard to find. This simply isn’t the case. Simple tools exist which for example list the past 10 minutes editing activity. Anyone can peruse these lists and check the edits are valid, and many people do. In addition, simple technical measures exist like checking for expletives.
OSM almost entirely sidesteps these issues because no NPoV is needed. We’re mapping facts after all – it’s hard to disagree that New York City exists. Thus any matter of opinion – which is potentially a large issue – is sidestepped.
Erroneous edits therefore drop in to one of three categories: honest mistakes, disagreement on the facts and malicious edits.
Honest mistakes are the most common and easily correctible mistake made with tools much like those wikipedia uses, plus the honesty which leads a new contributor to try and go back and fix things themselves.
Disagreements tend to happen in political hotspots. Anywhere you have a couple of major governments disagreeing over who owns some land for example. Think North/South Korea, Pakistan/India and the Turkish Republic of Northern Cyprus. In many of those cases the battle between contributors is much more minor than you’d expect – it’s not that a road exists, not that it may have two names in different languages. Not even that both names be shown, but which name is shown first!
This kind of passion I find far from destructive, if anything it’s an incredible testament to the amount of effort contributors are willing to put in to mapping their home area.
Malicious edits are probably the least significant and will always exist. We live in a world where most people most of the time want to do the right thing, and this is reflected in a good map. Malicious edits occur so infrequently and the tools are so good to spot them, that they last a very short amount of time. This is a good price to pay for all the other benefits of a Free map.
But let’s look at the alternative. If you have a problem with wikipedia or OSM you’re more than welcome to buy an encyclopaedia or map, use a commercial source or visit your local library. At no point would we want to force you to use these open and free tools. But for most people the small potential downside of having a bad article or map, and it is a small chance, is far outweighed by the benefits of it being free in both senses of the word.
What are those senses? There are two meanings in English for the word ‘free’. One is analogous to a free lunch, something physical you can be given at zero cost. The other has to do with your legal rights – what freedoms you have. In other languages these two meanings have separate words and the English conflation leads to confusion, much as the music industry would like you to believe that copyright infringement is the same as physical theft.
OSM is licensed openly. That means that not only is the picture of the map available for you to use under some set of terms like a traditional map. It means also that the picture, the underlaying data and pretty much everything else like the software is available. Not just available, but you are free to modify it all too.
Two things are required when you use OSM data – first that if you modify any of it, you would kindly distribute those modifications to everyone else under the same terms. This is called share-alike or the viral aspect of the license. The other thing we ask you to do is say where you go the data from in the first place.
These are small and very reasonable requests that bind the project together. Practically it means a number of things but we’ll just highlight one: It ensures feedback. Any changes have to be fed back in to the map and software continuously. This stops people from taking the map, improving it and then closing it off from other contributors. It acts to force a growing commons of data.
Of course many people disagree with the idea of contributing back reciprocally. A traditional mapping company would probably love to take OSM data of the countryside and stitch in their own, more complete, data for a city to make a complete map. This may seem reasonable from their perspective – they concentrate on a important area and get the less monetisable area for free.
From the community perspective it doesn’t make a whole lot of sense however. It would mean that the commercial version of the map was perpetually better than OSM and thus less and less effort would go in to OSM. Just that fact is enough to make it pointless, let alone that many would feel dirty simply helping a company complete it’s map for free. This is in contrast to a company which bases its products off a reciprocal map and makes efforts to improve it, on that understands that the rising tide floats all the boats.
Surely the traditional map provider would provide some data to help OSM though in exchange? In almost all cases this simply isn’t the case. Looking at their bottom line, rightly, there is very little incentive to help bring about their own extinction. Because that’s what is happening.
Recently at a conference I was accosted by a irate executive of a traditional mapping company, angry that they found it so hard to work with OSM. Not because of the quality of the data, the format or ontology but because the license would force them to give back. Of course we’re not forcing anyone to work with OSM data, but when you do these are our requirements.
Those companies would love those restrictions to go away, but without them there is little reason for anyone to contribute to the commons. Terry Pratchett succinctly sums this up with the song “wouldn’t it be nice, if everyone was nice”. Thus these two simple restrictions (reciprocity of sharing data modifications and attributing where you got it from) have evolved with many open projects to provide the right balance of carrot and stick, to provide the most basic common legal platform for contribution possible.
OSM providing all data public domain would of course be simpler, but I humbly assert it will be so simple that you would be left with a simple empty dataset. This is known as the tragedy of the commons – if you have a common resource which all can deplete free of the need to replenish it, it will run out. There are some exceptions to that rule, but OSM would, probably, quickly die in such a totally open environment. Besides, it’s worked brilliantly so far, so why change it?
Community is as important in OSM as any other project. If you consider an empty school building on a public holiday, it’s a pale comparison to the rich, noisy, living building when school is in session. And so it is too with open projects. Without a community OSM would be a dead end with a simple download to a static dataset, and many of these abound. Building community is hard, as anyone who has actually done it will tell you.
Community is a loose word. Many companies think they have a community when really they have a set of customers. How can you tell? A community can discuss amongst themselves and the network graph of those discussion looks like a map of the internet: complex because of all of the interconnections between nodes of the network. A set of customers looks like a lot of lines pointing one way toward the company, which often looks like a black hole because nothing comes back out.
Some fix that and provide a mailing list or forum for people to communicate. It’s a big step but usually not enough. A true community is able to jump out of the box they’ve been assigned. Traditional companies may allow you to fix their map for them in a fairly constrained way, and that’s a good step. But, can you fix their software? No. Can you help them with their data collection methodology? No.
You’re a worker ant, providing them with something valuable – map data. That works up to a point, especially if you have a huge volume of potential victims (I’m sorry, customers!) who can help you. You as the worker ant even get something back – a more usable and up to date map. But the motivations and the feeling you get from helping within such a constrained environment with little feedback is nothing compared to helping a truly reciprocal project like OSM.
Think about this for a second, most of those companies which open themselves up to you helping them fix their data employ a second tier to check what you’re submitting. They collect your error submissions and then pay someone to go out and check them. That’s stupid for two reasons.
One, you tell your customers at the first hurdle that you don’t in fact trust anything they do. That’s a huge disincentive to contribution. If you imagine all the hurdles you have to cross to edit a map: you have to care, you have to spend the time, you have to understand the problem and so on… At every stage you remove half the number of people who might contribute. Why preface all that by telling your customers you also don’t trust anything they do?
Two, if you’re paying for someone to go out mapping anyway why have all the user submission infrastructure. It makes little sense other than to help you optimise where you fix things and that’s a poor tradeoff compared to OSM.
Does this matter? Will there only be one map? Almost certainly not. OSM will evolve in to the best and most complete map possible but there is plenty of spare time in everyones lives and differing motivations to make perhaps 5-10 base maps possible, supported by different community or customer feedback because driving all those roads in a top down manner by more than a couple of companies doesn’t make a lot of financial sense.
Companies also tend to mess up the feedback loop substantially. OSM has always tried to minimise the time between you adding or fixing something in the map and you seeing that change reflected for all to see.
Consider this – that loop time for a traditional mapping company can be 18 to 24 months. In OSM it’s either 18-24 seconds or 18-24 minutes.
Why is that important? Because each time you fix something in OSM your brain gives you a little drop of seratonin, or something, that makes you feel good. And that comes from a quick feedback loop. With traditional companies your feedback loop is far, far too long. Anything more than a couple of minutes is too long because there’s no association of the act of fixing something with the good feeling. More often than not, you help fix something and it drops in to a black hole.
In fact, getting an email a month later that they fixed something is a detriment to you helping again. Surely, the user thinks, there must be a better system? And so they discover OSM.
At another conference, the host and interested parties wanted to build a new community map however at lunch we were left to fend for ourselves to find food. Consider this – if you can’t build a community of people to go to lunch or grab a beer, how will you organise one to map the world for you?
Maps are getting more detailed all the time. Every time you increase the depth and detail of a map from country to major roads, to primary roads, to secondary… all the way down to buildings. Every time you step up the depth level you exponentially increase the amount of data in the map. And with that, you exponentially increase the number of bugs in the map and the time and cost of fixing them or resurveying the whole map.
The logistical costs of producing maps in a top-down fashion pretty much levelled out at having fleets of cars driving around North America and Europe. Increasing the detail with footpaths would cost far more than the benefit any company could leverage if they tried to do it a similar way. Crowd sourcing this from customers and others is simply inevitable – there is no other way to do it. But many will likely try to add quality assurance in between their contributors and the map and thus limit the scope and depth of the contributions.
Likewise for base maps of just roads it makes sense today to almost exclusively crowd source the data. We’ve seen this begin to happen and like Mutual Assured Destruction, other companies will follow until there are no top down maps of the world.
Those maps will, at times and in certain areas, be better than OSM. But the growth of OSM is inexorable and like a freight train will ultimately roll over everything in its path. It may even happen before traditional companies figure this out and try to start seriously crowd sourcing data.
Thus, the future is bright for OSM. As the number of users screams upward so does the quantity and breadth of the data entered in to the map. As a moving target with a community behind it, OSM is incomparable with a top down map released on a quarterly basis.
Everywhere from crisis zones to mobile phones OSM is becoming the default map much as wikipedia became the default encyclopaedia, and that’s a beautiful thing to watch.