multimap have kindly agreed to let us use their office for the upcoming mapping party in London. We should be able to get some good data, so come along!
Author Archives: Steve Coast
OSM in google earth
You can now transform OSM data in to KML, the format used by google earth:

Ed Parsons interviews
Couple of Ed Parsons interviews which mention that mapping thingy: Nestoria blog and e-consultancy.com.
OSM on a mobile
richard sent me this pic a while ago:
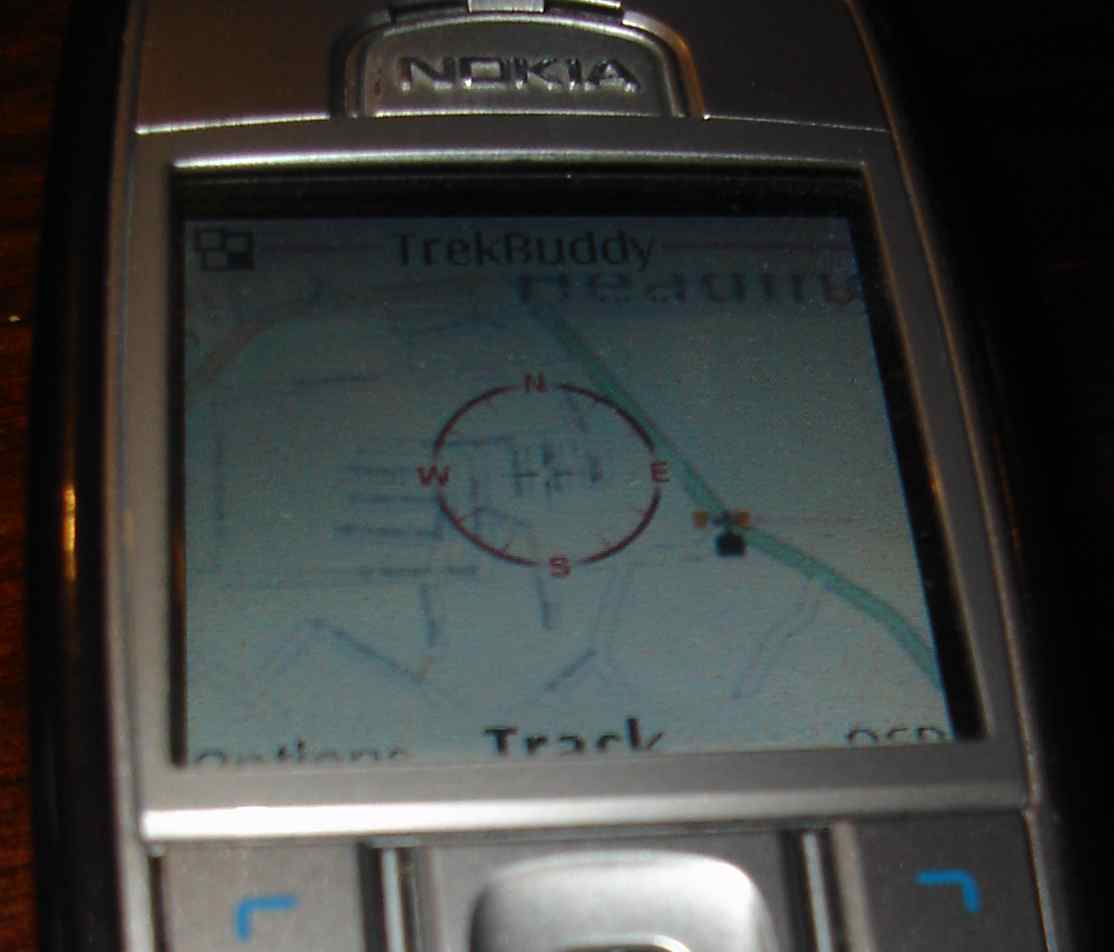
It’s from someones mobile at the xmas 2006 OSM meetup. It’s an osmarendered image put in to some magic app on a nokia mobile… If anyone remembers more info please add it to the comments. Anyway, a sign of things to come?
Map licensing, a view from the inside
An interesting post on the view from inside on licensing data.
If this data was owned collectively (that is to say, was not owned at all) and such basic factual documents were not seen as money making opportunities we would have so many advantages. Instead, we have a situation where hundreds of hours are being wasted simply because of outdated business models sadly adopted by our government. On top of this, such restrictions are stifling innovation. Google Maps may be able to afford to licence the OS data but the average bedroom developer cannot and so there is a less than optimal level of development in this area.
OSMonth Day 15
- Done lots of organising for the 3 upcoming parties and the conf over the past week.
- Figured out why the gpx import keeps stalling – someone keeps uploading mpegs which the importer thought were xml files in a strange charset, then crashing when it couldn’t parse it – fixed
- Brought back the wiki machine… seems the VM just isn’t up to it any more, will need to think how to proceed
State of the Map dates confirmed!
Thanks to the generous support from the School of Environment and Development at the University of Manchester we have dates and location confirmed for the first OSM conference!
- 14th and 15th July 2007
- Manchester university (map)
This means if you want to go to guadec then you can straight afterwards. We have a wiki page for organising things, please help by hacking it, adding transport ideas etc for people considering coming.
Turk meets GIS
Theres an absolutely fascinating use of Amazons Mechanical Turk (?) right now. There’s a HIT (a small task you get paid almost nothing to complete) that involves GIS:
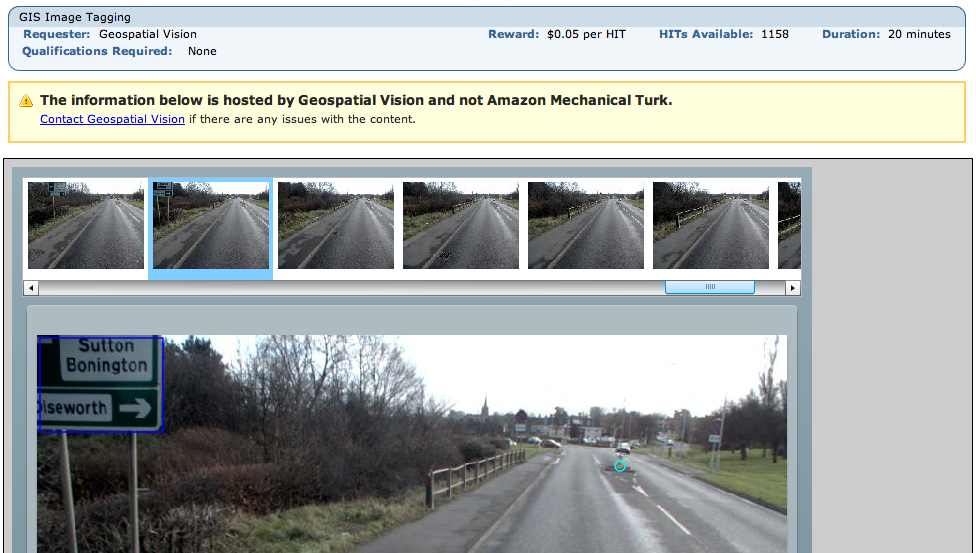
Geospatial Vision are paying people to do image recognition on sequential video stills from a car that they are apparently then recombining in to videos. These are on their (flash only, sigh) site.
You are paid 5 cents to tag 50 images with yellow lines, manholes, drains, bollards and pedestrian crossings. They are also, from looking at the videos, using these locations to then magically classify the sign type (one way, no entry, speed limit etc). Most images have only one feature if at all, there were about 2,000 HITs last night and at 25 frames a second that puts it at about an hour of footage for $100. That is insane.
If you wanted to get data out of it, the video stills themselves could be captured from your screen like the above screen shot and put back in to a movie. People and number plates can be seen in the images… and street signs so you could figure out where they are. You could add bad data – bollards in the sky or whatever. Amazon have various methods to combat these attacks. But it’s all academic as they’re putting at least some of the work on their site anyway.
It strikes me that this is just scratching the surface of the potential of this class of problem, Mechanical Turk is still only known to a small subset of tech people really. People with big data sets would want entire teams of lawyers to look at this and have Snow Crash-esque schemes to keep people from ‘stealing’ their precious data. Could you imagine the OS ever touching this with a barge pole?
The barrier to entry is a little high in that you have to create a flash app or similar if you want to do more interesting HITs but simpler ones are done automagically with forms by amazon. The other barrier is that like many other companies they think the entire world ends at the edge of CONUS so you can’t really make use of it unless you have a US bank account.
There’s another HIT which just asks for an idea from you – what small program would you like to see that doesn’t exist? I imagine the person who did that one just sitting back and browsing ideas for things to work on. How meta can you get?
So we now live in a world where you can effectively treat data storage (Amazon S3), processing (Amazon ECC) and mass non-linear human intelligence (Mechanical Turk) as infinitely cheap and available. You can get programming, design, legal advice and more from rentacoder, elance and more.
Given this, I can’t think of much that you don’t have covered in Phase 1 of your average business plan. Or to look at it another way, the google kids have been living in this world for maybe 4-5 years.
So readers, if you had a big dataset what would it be and how would you get it processed using the above? Best idea gets $10 worth of HITs.
Some news
nick notes that npe maps now covers the Isle of Man.
Theres a JOSM map rectification plugin over here that looks pretty.
Theres a book out with some of the best finds on gmaps aerial imagery from google sightseeing
OSMonth Day 14.5
- Spent the morning trying to build ruby bindings for mapnik, didn’t get anywhere, mailed mapnik-devel. update short debate on mailing list, looks easy if you know C++, mapnik, swig and python well enough but I don’t. Someone please make swig bindings for this and I’ll have your babies.
- brought back stevecam. It was pointing out my window and I forgot about it sorry